GMail has this feature where it will warn you if you try to send an email that it thinks might have an attachment.
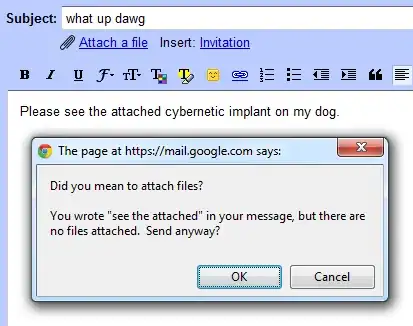
Because GMail detected the string see the attached in the email, but no actual attachment, it warns me with an OK / Cancel dialog when I click the Send button.
We have a related problem on Stack Overflow. That is, when a user enters a post like this one:
my problem is I need to change the database but I don't won't to create
a new connection. example:
DataSet dsMasterInfo = new DataSet();
Database db = DatabaseFactory.CreateDatabase("ConnectionString");
DbCommand dbCommand = db.GetStoredProcCommand("uspGetMasterName");
This user did not format their code as code!
That is, they didn't indent by 4 spaces per Markdown, or use the code button (or the keyboard shortcut ctrl+k) which does that for them.
Thus, our system is accepting a lot of edits where people have to go in and manually format code for people that are somehow unable to figure this out. This leads to a lot of bellyaching. We've improved the editor help several times, but short of driving over to the user's house and pressing the correct buttons on their keyboard for them, we're at a loss to see what to do next.
That's why we are considering a Google GMail style warning:
Did you mean to post code?
You wrote stuff that we think looks like code, but you didn't format it as code by indenting 4 spaces, using the toolbar code button or the ctrl+k code formatting command.
However, presenting this warning requires us to detect the presence of what we think is unformatted code in a question. What is a simple, semi-reliable way of doing this?
- Per Markdown, code is always indented by 4 spaces or within backticks, so anything correctly formatted can be discarded from the check immediately.
- This is only a warning and it will only apply to low-reputation users asking their first questions (or providing their first answers), so some false positives are OK, so long as they are about 5% or less.
- Questions on Stack Overflow can be in any language, though we can realistically limit our check to, say, the "big ten" languages. Per the tags page that would be C#, Java, PHP, JavaScript, Objective-C, C, C++, Python, Ruby.
- Use the Stack Overflow creative commons data dump to audit your potential solution (or just pick a few questions in the top 10 tags on Stack Overflow) and see how it does.
- Pseudocode is fine, but we use c# if you want to be extra friendly.
- The simpler the better (so long as it works). KISS! If your solution requires us to attempt to compile posts in 10 different compilers, or an army of people to manually train a bayesian inference engine, that's ... not exactly what we had in mind.