The CSV parser used in the jquery-csv plug-in
It's a basic Chomsky Type III grammar parser.
A regex tokenizer is used to evaluate the data on a char-by-char basis. When a control char is encountered, the code is passed to a switch statement for further evaluation based on the starting state. Non-control characters are grouped and copied en masse to reduce the number of string copy operations needed.
The tokenizer:
var tokenizer = /("|,|\n|\r|[^",\r\n]+)/;
The first set of matches are the control characters: value delimiter (") value separator (,) and entry separator (all variations of newline). The last match handles the non-control char grouping.
There are 10 rules that the parser must satisfy:
- Rule #1 - One entry per line, each line ends with a newline
- Rule #2 - Trailing newline at the end of the file omitted
- Rule #3 - First row contains header data
- Rule #4 - Spaces are considered data and entries should not contain a trailing comma
- Rule #5 - Lines may or may not be delimited by double-quotes
- Rule #6 - Fields containing line breaks, double-quotes, and commas should be enclosed in double-quotes
- Rule #7 - If double-quotes are used to enclose fields, then a double-quote appearing inside a field must be escaped by preceding it with another double quote
- Amendment #1 - An unquoted field may or may
- Amendment #2 - A quoted field may or may not
- Amendment #3 - The last field in an entry may or may not contain a null value
Note: The top 7 rules are derived directly from IETF RFC 4180. The last 3 were added to cover edge cases introduced by modern spreadsheet apps (ex Excel, Google Spreadsheet) that don't delimit (ie quote) all values by default. I tried contributing back the changes to the RFC but have yet to hear a response to my inquiry.
Enough with the wind-up, here's the diagram:
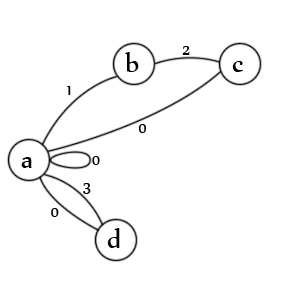
States:
- initial state for an entry and/or a value
- an opening quote has been encountered
- a second quote has been encountered
- an un-quoted value has been encountered
Transitions:
- a. checks for both quoted values (1), unquoted values (3), null values (0), null entries (0), and new entries (0)
- b. checks for a second quote char (2)
- c. checks for an escaped quote (1), end of value (0), and end of entry (0)
- d. checks end of value (0), and end of entry (0)
Note: It's actually missing a state. There should be a line from 'c' -> 'b' marked with state '1' because an escaped second delimiter means the first delimiter is still open. In fact, it would probably be better to represent it as another transition. Creating these is an art, there's no single correct way.
Note: It's also missing an exit state but on valid data the parser always ends on transition 'a' and none of the states are possible because there is nothing left to parse.
The Difference between States and Transitions:
A state is finite, meaning it can only be inferred to mean one thing.
A transition represents the flow between states so it can mean many things.
Basically, the state->transition relationship is 1->* (ie one-to-many). The state defines 'what it is' and the transition defines 'how it's handled'.
Note: Don't worry if the application of states/transitions doesn't feel intuitive, it's not intuitive. It took some extensive corresponding with somebody much smarter than I before I finally got the concept to stick.
The Pseudo-Code:
csv = // csv input string
// init all state & data
state = 0
value = ""
entry = []
output = []
endOfValue() {
entry.push(value)
value = ""
}
endOfEntry() {
endOfValue()
output.push(entry)
entry = []
}
tokenizer = /("|,|\n|\r|[^",\r\n]+)/gm
// using the match extension of string.replace. string.exec can also be used in a similar manner
csv.replace(tokenizer, function (match) {
switch(state) {
case 0:
if(opening delimiter)
state = 1
break
if(new-line)
endOfEntry()
state = 0
break
if(un-delimited data)
value += match
state = 3
break
case 1:
if(second delimiter encountered)
state = 2
break
if(non-control char data)
value += match
state = 1
break
case 2:
if(escaped delimiter)
state = 1
break
if(separator)
endOfValue()
state = 0
break
if(newline)
endOfEntry()
state = 0
break
case 3:
if(separator)
endOfValue()
state = 0
break
if(newline)
endOfEntry()
state = 0
break
}
}
Note: This is the gist, in practice there's a lot more to consider. For example, error checking, null values, a trailing blank line (ie which is valid), etc.
In this case, the state is the condition of things when the regex match block finishes an iteration. The transition is represented as the case statements.
As humans, we have a tendency to simplify low level operations into higher level abstracts but working with a FSM is working with low level operations. While states and transitions are very easy to work with individually, it is inherently difficult to visualize the whole all at once. I found it easiest to follow the individual paths of execution over and over until I could intuit how the transitions play out. It's king of like learning basic math, you won't be capable of evaluating the code from a higher level until the low level details start to become automatic.
Aside: If you look at the actual implementation, there are a lot of details missing. First, all impossible paths will throw specific exceptions. It should be impossible to hit them but if anything breaks they will absolutely trigger exceptions in test runner. Second, the parser rules for what is allowed in a 'legal' CSV data string are pretty loose so the code needed to handle a lot of specific edge cases. Regardless of that fact, this was the process used to mock the FSM prior to all of the bug fixes, extensions, and fine tuning.
As with most designs, it's not an exact representation of the implementation but it outlines the important parts. In practice, there are actually 3 different parser functions derived from this design: a csv-specific line splitter, a single-line parser, and a complete multi-line parser. They all operate in a similar manner, they differ in the way they handle newline chars.