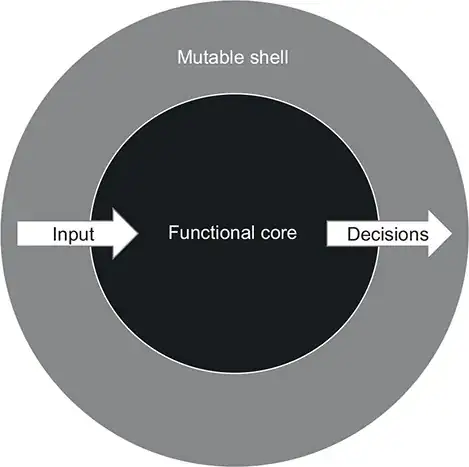
My understanding of "Functional Core, Imperative Shell" is basically that you do all the Input (I) in I/O first in the imperative shell, then you call your pure functions (in the functional core) to generate some result based on the input, and then in the imperative shell you take the result and do the Output (O) in I/O.
This has also been called Impureim sandwich by Mark Seemann.
To simplify things, you have three functions:
- An impure function to read inputs: () => Input
- A pure function: Input => Result
- An impure function to write outputs: Result => ()
What you have pointed out is very true: things are not always linear in this way.
- You can have a long running process (function) that needs to be fed new inputs while it is running. This can be because of performance reasons, e.g. you cannot read all orders from the database at once. Or it can be for logical reasons, e.g. you don't know which orders you need to get from the database before doing some calculations.
- You can have a long running process (function) that needs to output some data while it is running. Again, this can be for performance reasons, e.g. you cannot return a 4GB object at the end of the function call, so you need to insert data into the database in pieces while you are running. Or it can be for monitoring reasons, e.g. you want to display status to the user while you are running.
- Even a short running function might need to get data from different sources based on some logic, e.g. you do some calculations then then decide you want to grab data from source 1 or source 2 based on the results of the calculations, and then you need to do calculations based on the data returned from source 1 or source 2. Based on the result of those calculations you need to read data from source 3 or source 4, and this can go on and on...
I think in those cases (which are very common), you really cannot have a true "Functional Core, Imperative Shell".
I think the next best thing is an Honest Potentially-Functional Core, Imperative Shell.
That is, you create a potentially-functional core. That is a collection of potentially-pure functions.
Basically, your functions are for example:
- An impure function to read inputs: () => Input
- A potentially-pure function: (Input, () => MoreInputs1, () => MoreInputs2, SomeResults1 => (), SomeResults2 => (), SomeResults3 => SomeInputs3) => Result
- An impure function to write outputs: Result => ()
When the imperative shell calls the potentially-pure function, it passes impure functions for the following arguments (which are of type function):
- () => MoreInputs1
- () => MoreInputs2
- SomeResults1 => ()
- SomeResults2 => ()
- SomeResults3 => SomeInputs3
The "pure" thing about your potentially-pure function is that it declares all dependencies that would make it impure. This makes it an honest function.
See this article for more details about composing potentially-pure functions: https://divex.dev/knowledge-base/main/dependency-injection-can-be-functional/
I think there are other ways to create a potentially-functional core. I think the Haskell IO monad is one such way, but I am not sure.