Direct feedback
Is there any [..] form of a standard document to help document the project structure,
Documentation should be structured in the way that makes the most sense to the people reading it. There is no objectively superior method, other than simply instructing you how to write clearly (which has nothing to do with software development specifically).
The key here is to have consistent documentation which is not too terse (because it omits information) or too verbose (because it becomes a slog to read through). This is a very fine balance that needs to be tailored to how you expect this document to be used. E.g. the document best used for newcomers to the projects is usually not the document best used as a reference tool for developers experienced with the project.
Is there any tool [..] to help document the project structure
While it's certainly possible to document project structure, it quickly becomes apparent that you should also strive for consistency between projects so that you don't need to uniquely document every project.
I added a chapter on consistency further in the answer.
Is there any tool [..] to help document modules, what piece of code does what
If you're talking about describing the core (business) function, that's essentially what your technical analysis is for.
If you're talking about where to find these modules, that belongs to the "project structure" mention I made before.
Is there any tool [..] to help document what piece of code does what, what class contains which functionality
When you stick to known concepts and patterns, an experienced developer who doesn't know your application will usually find their way because they know the name of the pattern. Based on its name alone, I have a good idea what to expect in FooFactory (Foo instantiation), FooRepository (retrieving Foo objects from the data store), FooService (an endpoint for Foo communication), Foo (the data structure), FooExtensions (extension methods on Foo), etc.
When you don't stick to known concepts and patterns, you take on the responsibility of having to document your unique approach. That's not necessarily wrong to do (in some cases it is the best thing to do), but you do need to acknowledge that the documentation effort is non-zero and often significantly impacts the effort required to keep the codebase well documented.
Is there any tool [..] to help document where should this type of change goes and what layers specifically will be affected
That should be described in the change request itself. Depending on your project (and company) size, you'd expect significant changes to be first handled by a (technical) analyst who decides how to implement the change. The analyst delivers a technical analysis, which will list exactly what you're asking for.
If you don't have an analyst, I (as a developer) still tend to analyze my task before I start touching the code. Especially for large or regression-sensitive codebases, I tend to not touch the code until I fully understand the change I'm going to make in the codebase.
Initially, this looks like it takes extra time and effort to pre-analyze before developing, but it commonly pays back dividends. I usually don't have to change my approach mid-development, and I sometimes spot issues (either in the code or the requested change) that need clarifying before I start changing the code.
some times I make a draft word file to express where important functionality is placed in the code, but when the project grows big, this is very difficult
A well defined project structure remains understandable regardless of whether there are 10, 100 or 1000 classes/files in the project.
If your project structure starts buckling when more files are added to it, that means your project structure was not as clear as it should have been, but the problem was being masked because the codebase used to be sufficiently small for it to not really pose a problem.
Think of it this way: there are tens of thousands of files in C:\Program Files. But regardless of whether I've installed 10 or 100 applications, it takes me the same amount of time to find a given application's files. The same should be true of your projects. The path to any randomly selected file should remaing consistent regardless of how many other files there are in your project.
and when you talk about DB applications (stored procedures and functions) this is a disaster !!!!
Stored procedure-heavy applications are notorious for being hard to maintain. That's just a fact of life, and one of the reasons why I advocate moving away from them as the default solution (though I do admit that they can be useful in select use cases, but not as a default blanket approach to your application). But that's not an answer for you, your project architecture is already decided.
You're going to have to find a way to counter these maintenance difficulties by documenting/categorizing the stored procedures in a way that makes sense to you. This is a matter of both naming the sprocs/files and the folder structure ion which you store them.
I can't tell you what structure you should use. That very much depends on your specific needs and what makes the most sense to you (or your team).
I can't believe that no one tried to solve such a common problem.
I'm not trying to be facetious, but it's considerably better to avoid the problem rather than trying to find a solution to it. Solutions are unique to particular cases and solving it for one codebase doesn't automatically solve it for another. Preventative measures, however, are applicable to all projects and provide a blanket solution.
Consistency
If all your projects follow the same basic file and/or naming structure, it will be much easier to work in multiple projects and revisit them from time to time.
How you structure it is up to you (or your team). I'm just going to give you some examples of consistent structures I use.
- I tend to stick to the same basic project names: Domain, Database, Business, Web, API, Export, ... Of course this only applies for things that are common to most codebases, exceptions or unique additions can always exist for a given codebase.
- Every file goes in a folder, with exception of files that are related to the project itself (e.g. Global.asax.cs, Web.config, etc). All files that I create get sorted into folders.
- Extension methods and helper classes (i.e. static classes) belong to a "Helpers" folder in the project root. Subdivision of that folder is done based on how many files are in there.
- When not using a Domain project, all interfaces and base classes get a special "Base" subfolder. E.g. if my EF entities belong to the "Entities" folder, then the base abstract class all my entities derive from belongs to the "Entities/Base" folder. I don't like it when the base/derived classes are in the same folder because I don't like having to look through all the files to find the one base class.
- If there is a Domain project (which contains all contracts and domain-specific structure), its folder structure mirrors that of the projects (e.g. the
IFooRepository belongs to the "Database" folder since FooRepository : IFooRepository belongs to the Database project).
There is no one right answer. Pick any structure that makes sense to you (or your team) and stick to it as best as you can. If you keep up the consistency, you will notice that after having handled a few projects, all new project will feel familiar and the time needed to find your way in them is drastically reduced.
Learn to traverse the jungle
One note before I start this paragraph: this is not a replacement for clean coding. It's a collection of workaround tips in cases where clean code has already failed but you have to make do with what you have.
I once worked on a legacy governmental project where the code (i.e. the "text" files) was 1.3GB of 20-year-old undocumented spaghetti mess. For about a month, I was also the only developer on the project with no business knowledge whatsoever.
This taught me the invaluable skill of learning to find your way through a jungle of a codebase.
This is really just a list of tips and tricks that I've learned over the years. I'm open to expanding it if people want to suggest more entries via the comments. I'm writing the tips from a Visual Studio perspective but I expect most IDEs will have similar features to the ones I'm describing.
- Ctrl + Shift + F (as opposed to Ctrl + F) will list all matches in a summary window. This means that you can very quickly look for a keyword (or phrase) that you suspect to find in the code.
- When trying to find the source of a bug where the
Name property is being set to the wrong value, look for the phrase .Name =. The odds are very high that you will find it there (though it doesn't cover cases such as object initializers).
- Alternatively, you can rightclick the
Name property and find all references. This lists every usage, but in VS 2019 they are adding the feature to filter on usage (setting vs getting), which makes this tip superior to the previous one. Without that new feature, I tend to use both methods based on what works best for me in a given situation.
- If you're at a complete loss for the source of a bug, it can help to employ a binary search-like tactic whereby you comment out part of the code and try to reproduce the bug. If it still occurs, you know it's not in the commented code. If it doesn't occur, then you know it's somewhere in the commented code. You can repeat this to refine your approach and very quickly home in on the immediate vicinity of a bug.
- Learn to guesstimate method or property names so you can try to ctrl+F them. E.g. when looking for a method that returns a
Foo object, search for something like public Foo Get because it's likely to find matches for things like public Foo GetFooById(int id) or similarly structured methods. If your codebase uses consistent naming, your find results are more likely to find what you're looking for.
Even Notepad++ can be a tremendous help sometimes. When you press Ctrl + Shift + F, you get an advanced find window. To showcase how finetuned your search can be, an example:
We're dealing with a bug where a Foo object is being saved to the database containing wrong data. We have no idea how to begin looking for it. But we know that since it's being saved to the db, our unit of work's Commit() method is being called. That gives us a keyphrase to look for.
However, this method is used all over the place for all of our entities. We want to refine it to find Foo-specific instances.
A good first attempt could be:
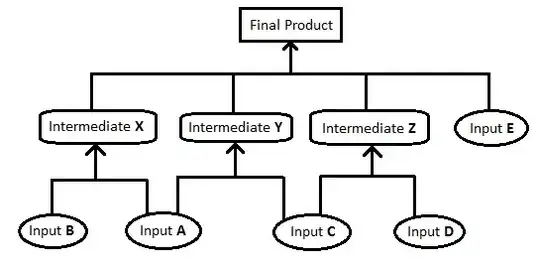
We're looking for the Commit() method call, but we're limiting our search to files that follow the Foo*.cs format, i.e. C# code from classes whose name starts with Foo. If you used a clear naming scheme, you're most commonly going to expect to find hits in files such as FooRepository.cs, which matches the filter we've defined.
This is just a simple example, but it's easy to see that when your filenames (and class names) follow a consistent pattern, that you can use this pattern to find these specific files.