I rarely use a tail pointer for linked lists and tend to use singly-linked lists more often where a stack-like push/pop pattern of insertion and removal (or just linear-time removal from the middle) suffices. It's because in my common use cases, the tail pointer is actually expensive, just as making the singly-linked list into a doubly-linked list is expensive.
Often my common case usage for a singly-linked list might store hundreds of thousands of linked lists which only contain a few list nodes each. I also generally don't use pointers for linked lists. I use indices into an array instead since the indices can be 32-bit, e.g., taking half the space of a 64-bit pointer. I also generally don't allocate list nodes one at a time and instead, again, just use a big array to store all the nodes and then use 32-bit indices to link the nodes together.
As an example, imagine a video game using a 400x400 grid to partition a million particles which move around and bounce off of each other to accelerate collision detection. In that case, a pretty efficient way to store that is to store 160,000 singly-linked lists, which translates to 160,000 32-bit integers in my case (~640 kilobytes) and one 32-bit integer overhead per particle. Now as particles move around on the screen, all we have to do is update a few 32-bit integers to move a particle from one cell to the other, like so:
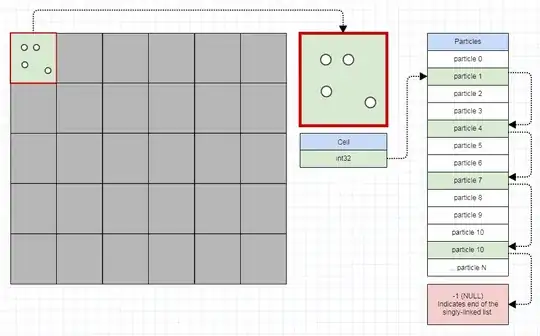
... with the next index ("pointer") of a particle node serving as either an index to the next particle in the cell or the next free particle to reclaim if the particle has died (basically a free list allocator implementation using indices):
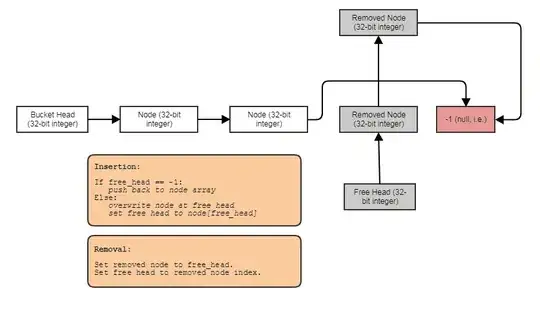
The linear-time removal from a cell isn't actually an overhead since we're processing the particle logic by iterating through the particles in a cell, so a doubly-linked list would just add overhead of a kind that isn't beneficial at all in my case just as a tail wouldn't benefit me at all either.
A tail pointer would double the memory usage of the grid as well as increasing the number of cache misses. It also requires insertion to require a branch to check if the list is empty instead of being branchless. Making it a doubly-linked list would double the list overhead of each particle. 90% of the time I use linked lists, it's for cases like these, and so a tail pointer would actually be relatively quite expensive to store.
So 4-8 bytes actually isn't trivial in most of the contexts in which I use linked lists in the first place. Just wanted to chip in there since if you are using a data structure to store a boatload of elements, then 4-8 bytes may not always be so negligible. I actually use linked lists to reduce the number memory allocations and amount of memory required as opposed to, say, storing 160,000 dynamic arrays that grow for the grid which would have an explosive memory use (typically one pointer plus two integers at least per grid cell along with heap allocations per grid cell as opposed to just one integer and zero heap allocations per cell).
I often find many people reaching for linked lists for their constant-time complexity associated with front/middle removal and front/middle insertion when LLs are often a poor choice in those cases due to their general lack of contiguity. Where LLs are beautiful to me from a performance standpoint is the ability to just move one element from one list to another by just manipulating a few pointers, and being able to achieve a variable-sized data structure without a variable-sized memory allocator (since each node has a uniform size, we can use free lists, e.g.). If each list node is being individually allocated against a general-purpose allocator, that's usually when linked lists fare much worse compared to the alternatives, and it's often through misguided use in those contexts where they end up getting a bad reputation in languages like C++.
I would instead suggest that for most of the cases where linked lists serve as a very effective optimization over straightforward alternatives, the most useful forms are generally singly-linked, only need a head pointer, and do not require a general-purpose memory allocation per node and can instead often just pool memory already allocated per node (from a big array already allocated in advance, e.g.). Also each SLL would generally store a very small number of elements in those cases, like edges connected to a graph node (many tiny linked lists as opposed to one massive linked list).
It's also worth keeping in mind that we have a boatload of DRAM these days but that's the second slowest type of memory available. We're still at something like 64 KB per core when it comes to the L1 cache with 64-byte cache lines. As a result, those little byte savings can really matter in a performance-critical area like the particle sim above when multiplied millions of times over if it means the difference between storing twice as many nodes into a cache line or not, e.g.

