Files in various code versioning systems typically gain bugs at one commit and remain bugged until they are fixed in another commit. This is because there are two popular methods for using versioning: file locks and merges. In the case of a file lock, developers lock files they're working on so nobody else can make changes. After unlocking, the other developers must then checkout the same file, ensuring that those changes won't be lost.
In a merging code versioning system, the main branch stores all of the commits from all branches merged into it, creating a linear history. This usually works on the concepts of diffs/patches, meaning that a commit that introduces a bug from one branch won't be automatically wiped out from a commit in another branch that is merged in later. In some rare cases, conflicts occur, and then a manual resolution is required. Bugs usually survive such merges, too, so they still appear continuously through the master branch's timeline.
No matter how many branches or developers you have working on a project, you can practically guarantee that simply by identifying the last known good commit before the bug, and last known bad commit for a bug (usually the current ref position), you can clearly isolate the commit that caused the bug, no matter which branch it occurred in. This is a side-effect of the linear nature of the logs and how they integrate to the main branch.
You can always identify the maximum search time for finding a bug by counting the number of commits from the last known good to the last known bad commit, and finding log2(x). You can often search an entire repository's history for a bug in well less than 20 iterations (16,000 commits, for example, is just 14 iterations). If you know the release a bug appeared in, that's usually in the order of about 5-10 iterations (your mileage may vary).
I only have experience with SVN and Git, but it's clear that any system that uses something better than "zip all the files in the repo into a hidden commit folder" (e.g. using literal file system snapshots) should have roughly the same logarithmic performance for finding bugs. There will always be just one linear log that needs to be read, ignoring all branches, even those that were later discarded or rebased, because the timeline will always appear linear.
For a crazy example, take a look at this image:
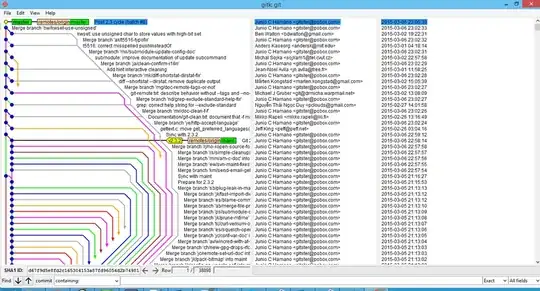
In this image, they show how Git works. And while Git is doing the job it was given, this is not a pretty sight. However, you'll notice how each commit nicely lines up linearly, despite merging from a ton of different branches at different times. Of course, there are tools to fix this history so its legible again (for example, this article about how they ended up in that mess).
The point is, the versioning system will keep things straight for you, so a simple binary search in a simple linear history is really all that's required.