I'm looking for examples of creating, handling and managing error numbers/codes.
To understand what I'm takling about, let's take example scenario: (EU - end user, IT - it helpdesk)
EU: - (calls IT) something's wrong
IT: - what happened?
EU: - it says "cannot create xyz"
IT: - what have you done?
EU: - ummm....
(conversation continues for another gazillion years)
... and exception that produces message cannot create xyz is being thrown in dozen places in whole system, so IT guy doesn't know where to look for.
Another approach (which I really like and would like to use) is for example:
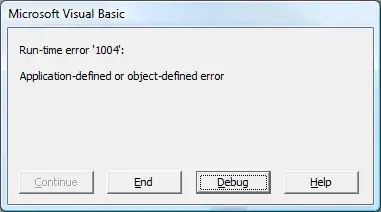
Now, when EU calls IT, whole conversation looks like this:
EU: - I have error 1004
IT: - ok, thanks, we'll take a look
Having error code, IT guy instantly knows where to look for error. He doesn't need to ask EU to provide loads of misleading details, he just can sit down and work or if he knows why, explain that this is intentional error because EU did something wrong.
Sounds like flowers and donuts, doesn't it?
But what are best practices to achieve this behaviour?
Let's assume that this is Java and we're building app from scratch. What I know so far is that I cannot get error codes from database, because if Exception is being thrown, I cannot rely on external sources.
This leads to problems with teamwork. Let's say that John, Paul and Adam assumed that they will use error codes while writing their app, and they will generate errors incrementaly. I see possible collision, when John wants to mark exception message in code using number #256, but Paul doesn't know about that and creates his own exception, also with #256 related it, and uses this exception in few dozens of places in app. At the end of the day noone knows what error #256 really means.
So maybe there's another approach - use small but handy one-table web app that will handle generating error numbers, so John, Paul and Adam just can click "generate" when they want new unique error number?
Above elaborate also leads to another question - what are best practices to set error codes? In exceptions themself, like this:
public class FooException extends Exception {
public FooException() { super(); }
public FooException(String message) { super("Error #256 - xyz is forbidden"); }
public FooException(String message, Throwable cause) { super("Error #256 - xyz is forbidden", cause); }
public FooException(Throwable cause) { super(cause); }
}
or:
try{
(some stuff)
} catch (FooException ex){
System.out.println("Error #256 - you cannot do xyz in here");
}
I suspect second option is better, because it indicates unique, specific place in code in whole project, but this looks harder to manage.
Any thoughts? Any practices? Advices? Thanks.