 I want to identify most matching sentence using some pattern. That means by using java algorithm I want to create identical value for each sentences.Each sentence when entering to that algorithm can be out some kind of identical value. How can I develop it? What can I refer any web sites do you know? What sort of sites should I look for? Actually I want clarify about when I'm giving as ex: 5 sentence to algorithm that possible to generate some kind of 5 values.Then I compare with those values with previously generated values(I should be store those values in my database) and get the gap between new 5 value and previously stored values.Then I get the distance and I selected most suitable sentence as most lowest gap value.
I want to identify most matching sentence using some pattern. That means by using java algorithm I want to create identical value for each sentences.Each sentence when entering to that algorithm can be out some kind of identical value. How can I develop it? What can I refer any web sites do you know? What sort of sites should I look for? Actually I want clarify about when I'm giving as ex: 5 sentence to algorithm that possible to generate some kind of 5 values.Then I compare with those values with previously generated values(I should be store those values in my database) and get the gap between new 5 value and previously stored values.Then I get the distance and I selected most suitable sentence as most lowest gap value.
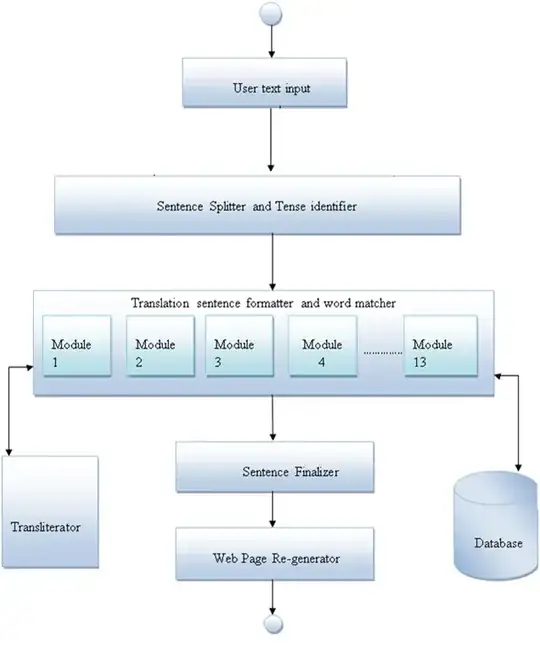
I'm use those things for my machine translation tool. As an example we think using my ruled based translation model generate 2 sentences. 1. I want eat an apple. 2. I want eat a house. In my corpus we think more sentences include and I store values for sentences in my database. (Value assign part is I don’t know yet) I want to create java algorithm to assign value for each sentence. As an example if we think Sentence 1 value: 250.8 Sentence 2 value : 290.5
Database included values 248, 400,800 Then I got the difference. So we can see here most minimum difference get for 250.8 and most suitable sentence is 1 one.