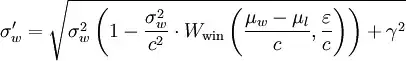This argument assumes you have no problem with typing unicodes nor reading greek letters
Here's the argument: would you like pi or circular_ratio?
In this case, I'd prefer pi to circular_ratio because I've learned about pi since I was in grade school and I can expect the definition of pi is well ingrained to every programmers worth his salt. Therefore I wouldn't mind typing π to mean circular_ratio.
However, what about
winner_sigma_new = ( winner_sigma ** 2 *
( 1 -
( winner_sigma ** 2 -
general_uncertainty ** 2
) * Wwin(t,e)
) + dynamics ** 2
)**.5
or
σw_new = (σw**2 * (1 - (σw**2)/(c**2)*Wwin(t, e)) + γ**2)**.5
To me, both versions are equally opaque, just like pi or π is, except I didn't learn this formula in grade school. winner_sigma and Wwin means nothing to me, or to anyone else reading the code, and using neither σw doesn't make it any better.
So, using descriptive names, e.g. total_score, winning_ratio, etc would increase readability much better than using ascii names that merely pronounce greek letters. The problem isn't that I can't read greek letters, but I can't associate the characters (greek or not) with a "meaning" of the variable.
You certainly understood the problem yourself when you commented: You should have seen the paper. It's just eight pages.... The problem is if you base your variable naming on a paper, which chooses single-letter names for conciseness rather than readability (irrespective whether they're greek), then people would have to read the paper to be able to associate the letters with a "meaning"; this means you're putting an artificial barrier for people to be able to understand your code, and that's always a bad thing.
Even when you live in an ASCII-only world, both a * b / 2 and alpha * beta / 2 are an equally opaque rendering of height * base / 2, the triangle area formula. The unreadability of using single-letter variables grows exponentially as the formula grows in complexity, and the AllegSkill formula is certainly not a trivial formula.
Single letters variable is only acceptable as a simple loop counter, whether they are greek single-letters or ascii single-letter, I don't care; no other variables should consist solely of a single letter. I don't care if you use greek letters for your names, but when you do use them, make sure I can associate those names with a "meaning" without needing to read an arbitrary paper somewhere else.
When in grade school, I definitely wouldn't mind seeing mathematical expressions using symbols such as: +, -, ×, ÷, for basic arithmetics and √() would be a square-root function. After I graduated grade school, I wouldn't mind the addition of a shiny new symbols: ∫ for integration. Note the trend, these are all operators. Operators are much more heavily used than variable names, but they are less often reused for an entirely different meaning (in the case where mathematicians reuse operators, the new meaning often still holds some basic properties of the old meaning; this is not the case for when reusing variable names).
In conclusion, no, it's not bad to use Unicode characters for variable names; however, it's always bad to use single letter names for variable names, and being allowed to use Unicode names is not a license to use single letter variable names.