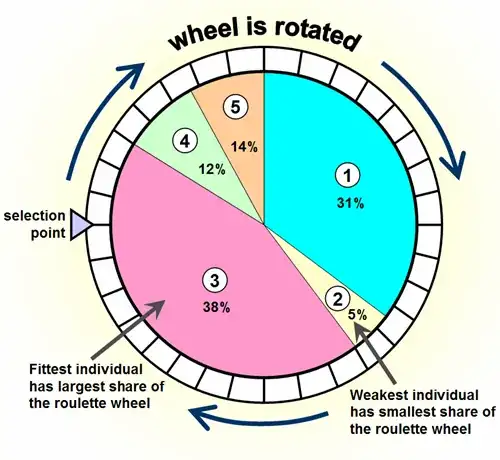
This gist is doing exactly what you are asking for.
public static Random random = new Random(DateTime.Now.Millisecond);
public int chooseWithChance(params int[] args)
{
/*
* This method takes number of chances and randomly chooses
* one of them considering their chance to be choosen.
* e.g.
* chooseWithChance(0,99) will most probably (%99) return 1
* chooseWithChance(99,1) will most probably (%99) return 0
* chooseWithChance(0,100) will always return 1.
* chooseWithChance(100,0) will always return 0.
* chooseWithChance(67,0) will always return 0.
*/
int argCount = args.Length;
int sumOfChances = 0;
for (int i = 0; i < argCount; i++) {
sumOfChances += args[i];
}
double randomDouble = random.NextDouble() * sumOfChances;
while (sumOfChances > randomDouble)
{
sumOfChances -= args[argCount -1];
argCount--;
}
return argCount-1;
}
you can use it like that:
string[] fruits = new string[] { "apple", "orange", "lemon" };
int choosenOne = chooseWithChance(98,1,1);
Console.WriteLine(fruits[choosenOne]);
The above code will most probably (%98) return 0 which is index for 'apple' for the given array.
Also, this code tests the method provided above:
Console.WriteLine("Start...");
int flipCount = 100;
int headCount = 0;
int tailsCount = 0;
for (int i=0; i< flipCount; i++) {
if (chooseWithChance(50,50) == 0)
headCount++;
else
tailsCount++;
}
Console.WriteLine("Head count:"+ headCount);
Console.WriteLine("Tails count:"+ tailsCount);
It gives an output something like that:
Start...
Head count:52
Tails count:48