What seems to have not been mentioned so far are the concepts of an unstable algorithm and an ill-conditioned problem. I'll address the former first, as that seems to be a more frequent pitfall for novice numericists.
Consider the computation of the powers of the (reciprocal) golden ratio φ=0.61803… ; one possible way to go about it is to use the recursion formula φ^n=φ^(n-2)-φ^(n-1), starting with φ^0=1 and φ^1=φ. If you run this recursion in your favorite computing environment and compare the results with accurately evaluated powers, you'll find a slow erosion of significant figures. Here's what happens for instance in Mathematica:
ph = N[1/GoldenRatio];
Nest[Append[#1, #1[[-2]] - #1[[-1]]] & , {1, ph}, 50] - ph^Range[0, 51]
{0., 0., 1.1102230246251565*^-16, -5.551115123125783*^-17, 2.220446049250313*^-16,
-2.3592239273284576*^-16, 4.85722573273506*^-16, -7.147060721024445*^-16,
1.2073675392798577*^-15, -1.916869440954372*^-15, 3.1259717037102064*^-15,
-5.0411064211886014*^-15, 8.16837916750579*^-15, -1.3209051907825398*^-14,
2.1377864756200182*^-14, -3.458669982359108*^-14, 5.596472721011714*^-14,
-9.055131861349097*^-14, 1.465160458236081*^-13, -2.370673237795176*^-13,
3.835834102607072*^-13, -6.206507137114341*^-13, 1.004234127360273*^-12,
-1.6248848342954435*^-12, 2.6291189633497825*^-12, -4.254003796798193*^-12,
6.883122762265558*^-12, -1.1137126558640235*^-11, 1.8020249321541067*^-11,
-2.9157375879969544*^-11, 4.717762520172237*^-11, -7.633500108148015*^-11,
1.23512626283229*^-10, -1.9984762736468268*^-10, 3.233602536479646*^-10,
-5.232078810126407*^-10, 8.465681346606119*^-10, -1.3697760156732426*^-9,
2.216344150333856*^-9, -3.5861201660070964*^-9, 5.802464316340953*^-9,
-9.388584482348049*^-9, 1.5191048798689004*^-8, -2.457963328103705*^-8,
3.9770682079726053*^-8, -6.43503153607631*^-8, 1.0412099744048916*^-7,
-1.6847131280125227*^-7, 2.725923102417414*^-7, -4.4106362304299367*^-7,
7.136559332847351*^-7, -1.1547195563277288*^-6}
The purported result for φ^41 has the wrong sign, and even earlier, the computed and actual values for φ^39 share no digits in common (3.484899258054952*^-9for the computed version against the true value7.071019424062048*^-9). The algorithm is thus unstable, and one should not use this recursion formula in inexact arithmetic. This is due to the inherent nature of the recursion formula: there is a "decaying" and "growing" solution to this recursion, and trying to compute the "decaying" solution by forward solution when there is an alternative "growing" solution is begging for numerical grief. One should thus ensure that his/her numerical algorithms are stable.
Now, on to the concept of an ill-conditioned problem: even though there may be a stable way to do something numerically, it may very well be that the problem you have just cannot be solved by your algorithm. This is the fault of the problem itself, and not the solution method. The canonical example in numerics is the solution of linear equations involving the so-called "Hilbert matrix":
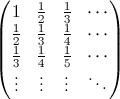
The matrix is the canonical example of an ill-conditioned matrix: trying to solve a system with a large Hilbert matrix might return an inaccurate solution.
Here's a Mathematica demonstration: compare the results of exact arithmetic
Table[LinearSolve[HilbertMatrix[n], HilbertMatrix[n].ConstantArray[1, n]], {n, 2, 12}]
{{1, 1}, {1, 1, 1}, {1, 1, 1, 1}, {1, 1, 1, 1, 1}, {1, 1, 1, 1, 1,
1}, {1, 1, 1, 1, 1, 1, 1}, {1, 1, 1, 1, 1, 1, 1, 1}, {1, 1, 1, 1, 1,
1, 1, 1, 1}, {1, 1, 1, 1, 1, 1, 1, 1, 1, 1}, {1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1}, {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1}}
and inexact arithmetic
Table[LinearSolve[N[HilbertMatrix[n]], N[HilbertMatrix[n].ConstantArray[1, n]]], {n, 2, 12}]
{{1., 1.}, {1., 1., 1.}, {1., 1., 1., 1.}, {1., 1., 1., 1., 1.},
{1., 1., 1., 1., 1., 1.}, {1., 1., 1., 1., 1., 1., 1.},
{1., 1., 1., 1., 1., 1., 1., 1.}, {1., 1., 1., 1., 1., 1., 1., 1., 1.},
{1., 1., 1., 0.99997, 1.00014, 0.999618, 1.00062, 0.9994, 1.00031,
0.999931}, {1., 1., 0.999995, 1.00006, 0.999658, 1.00122, 0.997327,
1.00367, 0.996932, 1.00143, 0.999717}, {1., 1., 0.999986, 1.00022,
0.998241, 1.00831, 0.975462, 1.0466, 0.94311, 1.04312, 0.981529,
1.00342}}
(If you did try it out in Mathematica, you'll note a few error messages warning of the ill-conditioning appearing.)
In both cases, simply increasing the precision is no cure; it will only delay the inevitable erosion of figures.
This is what you might be faced with. The solutions might be difficult: for the first, either you go back to the drawing board, or wade through journals/books/whatever to find if somebody else has come up with a better solution than you have; for the second, you either give up, or reformulate your problem to something more tractable.
I'll leave you with a quote from Dianne O'Leary:
Life may toss us some ill-conditioned problems, but there is no good reason to settle for an unstable algorithm.