What's a topic?
We define a topic as a Wikidata item of a given wikilink extracted from a given piece of Wikipedia content.
General architecture
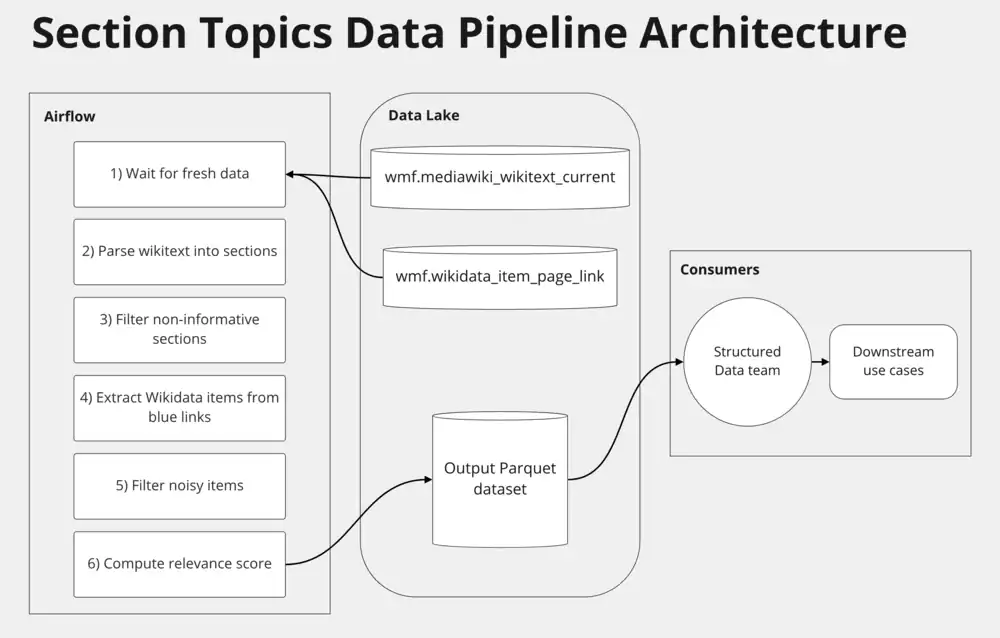
How it works
The data pipeline is implemented as an Airflow job and breaks down into the following steps:
- two sensors that give green lights as soon as fresh data is available in the Data Lake;
- one Python Spark task that takes as input Wikipedias wikitext, Wikidata item page links, and outputs the section topics dataset.
A look at the data
Here is how a row of data looks like (manually hyperlinked if the reader wishes to check it):
| snapshot | wiki_db | page_namespace | revision_id | page_qid | page_id | page_title | section_index | section_title | topic_qid | topic_title | topic_score |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2023-01-16 | enwiki | 0 | 1127523670 | Q36724 | 841 | Attila | 5 | Solitary kingship | Q3623581 | Arnegisclus | 1.13 |
Data processing flow
- Gather the content of top-level sections, lead section included;
- filter out sections that don't convey relevant topics, such as External links. See phab:T318092 and phab:T323504 for more details;
- extract Wikidata items from wikilinks: the so-called section topics;
- filter out noisy topics, such as dates. See phab:T323597 and phab:T323036 for more details;
- compute topics relevance score.
Note that we:
- resolve redirect pages;
- optionally separate media links from the main dataset.
Relevance score
We define relevance as a score that measures to what extent a given topic helps summarize and understand a given piece of Wikipedia content. This enables topic ranking and is computed as a term frequency-inverse document frequency (TF-IDF) weight based on the distribution of topics.
We must distinguish between article-level and section-level relevance, which summarize a Wikipedia article and a Wikipedia article section respectively. They follow slightly different implementations:
- the former is a custom weight, where the TF component is computed across Wikipedias by leveraging the language-agnostic nature of Wikidata items;
- the latter is a classic one, i.e., computed within the same Wikipedia;
- both compute the IDF component within the same Wikipedia.
As a result, we expect article-level relevance to be much more meaningful than section-level one, due to the much larger amount of topics that contribute to the computation. Moreover, TF-IDF doesn't perform well in case of short content, which is likely to impact relevance of short sections with few topics.