Statistics is your friend. I get it, you have a failed device, you wonder is this my fault? is it safe to ship in volume? what happens if this really is an issue and we ship 10,000 units to the field? All signs that you give a crap and that you're probably a conscientious designer/engineer.
But the fact is, you have one failure and the human foibles of confirmation bias apply to negative situations as readily as positive situations. You've had one failure, with no definite cause. Unless you know of an event that precipitated this effect then this is just anxiety.
This is ESD. Can I prove that it is ESD? - Maybe/maybe not - if you ship me the part and I spend big $$ to delid it and run it through different tests like SEM and SEM with surface contrast enhancement, maybe. I've had many cases where I deliberately zapped a device as part of ESD qualification, the device failed and yet it took a good 30 hours to find the failure point. It was important to understand the failure mechanisms and the activation energy so the hunt was necessary (if apparently wasteful) but fully half the time we couldn't see the failure point. And that was after a FMEA analysis and design guided elimination of location.
People have the false idea that ESD always means explosions and chip guts vomited all over with molten Si and acrid smoke. You do see this sometimes, but often it is just a tiny nanometer scale pinhole in the gate oxide that has ruptured. It may have happened a long time ago and over time it failed because of parametric shift.
In fact during ESD tests we use the Arrhenius equation to predict failure. We zap the devices at various levels and different models (source impedances) and then we cook the little b***rds for hours and track them over time to be able to glean the failure mode and thus predict future performance. You can easily have a 1000's of chips on boards running in environment chambers for months at a time. It's all part of "qual" - i.e. qualification.
The key effect we're always looking for for _some_failure modes is EOS (Electrical Overstress). It can be induced by ESD or other situations. I modern processes the tolerance to gate level EOS inside the chip is maybe 15% max. (That's why running the chip at it's intended MAX Vss rail is so important). EOS can manifest itself months later. The heat from operation would be like a mini accelerated lifetime test ( you're just not applying the Arrhenius equation, and it's not controlled).
If you want a better understanding look up the JEDEC ESD22 standards that describe the MM (Machine Model) and HMB (Human Body model) that describes the test probes and charging.
Here is snip of the model from JEDEC JESD22-A114C.01 (March 2005).
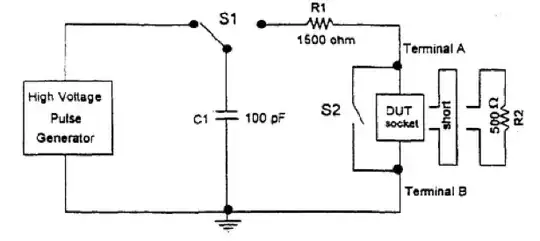
You sort of notice how it looks kinda of similar to your circuit? and the values are even kinda close, and this is used with the right voltage levels to blow the crap out of the ESD structures.
So what you need to do is:
-scrap that board
- track it's provenance, lot number and who handled it
- keep this info in a database (or spreadsheet)
- note in dB that you suspect ESD
- track all failures
- check the data over time.
- institute manufacturing controls so you can track.
- relax - you're doing fine.