Firstly, I am not the EE type, but I do have a petty good foundation on physics work on a pretty low level. I was wondering what mechanism it is that measures the magnetic indentation on hard drive platter (if that's even the case), and/or the specifications and variances that determines a 1 or 0.
Asked
Active
Viewed 629 times
3 Answers
11
Like Mark said it's the changes in polarization which is used to encode the data; a magnetic head won't see a static field.
Until some years ago recording was longitudinal, which means the fields were horizontal.
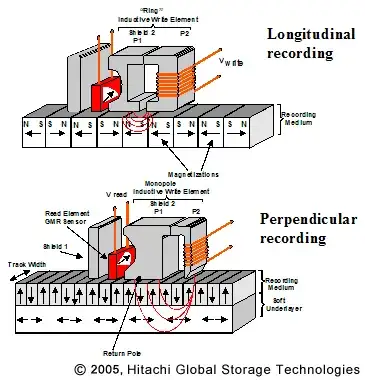
Growing hard disk capacities required a different way: perpendicular recording. The image shows that you can record bits closer together. Currently hard disks have capacities of over 100Gb/in\$^2\$, and it is expected that this technology can achieve 10 times that.
stevenvh
- 145,145
- 21
- 455
- 667
-
100 GB/in2? In only one plate? Amazing! – clabacchio May 23 '12 at 07:29
-
@clabacchio - well, a 3TB drive will probably use 3 or 4 platters, but that density is for each of them, yes. That's 80nm \$\times\$ 80nm for 1 bit. Amazing indeed. – stevenvh May 23 '12 at 07:40
-
@clabacchio note that it's Gbit/in^2, not GB/in^2, though! – exscape May 23 '12 at 10:13
-
@exscape still remarkably :) – clabacchio May 23 '12 at 10:54
-
http://www.hwupgrade.it/immagini/hdd_dens_1.jpg – clabacchio May 23 '12 at 16:55
-
@clabacchio - wow, 1900Gb/in\$^2\$! Bit that doesn't necessarily contradict the 1000Gb/in\$^2\$ I mention in my answer. That was what is expected possible with perpendicular recording. It's possible that after 2014 an other technology must be used. – stevenvh May 23 '12 at 17:11
-
@stevenvh probably in a few years SSD will be the leading technology... – clabacchio May 23 '12 at 17:35
-
@clabacchio - I think we'll still have to wait a while for that. Hard disks are currently 5 cent/GB, an SSD is still 1 euro/GB. – stevenvh May 23 '12 at 17:40
10
Not an expert on hard drives but its not really an "indentation" unless that has a different meaning in physics.
The "disk" contains a huge number of magnetized regions (really its a ferrous thin film on the disk), when writing to the disk the polarization of these regions is changed by the write head. The actual data, the ones and zeros, is encoded into a series of transitions from one polarization to another. One polarized region isn't really 1 bit, rather the timing of transitions from one polarization to another is what determines if a one or a zero is "read". See http://en.wikipedia.org/wiki/Run-length_limited for a standard coding method.
The read/write heads themselves are really just magnetic coils that can either detect the polarization of the field generated by the disk (read), or induce a polarization on the disk (write).
Mark
- 11,627
- 1
- 31
- 38
-
The polarization is what I was reffering to as indentations. Basically the induction of the field read by the head. – Chad Harrison May 22 '12 at 21:26
-
1Gotcha, I think what your looking to understand is then the encoding part. In many signaling schemes you don't want long strings of zero's or one's as without a transition it becomes difficult to maintain timings. RLE type encoding schemes attempt to guarantee a certain frequency of transitions in the physical medium regardless of the actual data. A similar method is used to avoid biasing the differential lines in ethernet (and for timing). – Mark May 22 '12 at 21:32
-
I should add that this type of encoding is generally used when the "clock" and the "data" are combined into a one signal. This is done most often in signals that need to travel a distance through an unknown environment. Ethernet, and digital audio via S/PDIF are examples, hard drives are another although the reasoning for doing this in a hard drive is mostly that there is no clock, you could i guess encode a clock track next to every data track but you would lose space and since every track on the disk has a different circumference, thus clock, you can't have just 1 master clock. – Mark May 22 '12 at 21:50
-
5
The storage of information on disk is somewhat similar to the representation of information in a barcode. Each location on a disk track is polarized in one of two ways, equivalent to the white and black areas of a barcode; as with a barcode, these polarized regions have various widths which are used to code data. The actual encoding is different, however, since barcodes are generally used to hold either decimal digits or characters chosen from a relatively small set (43 characters in the case of code 39), whereas disk drives are used to store base-256 bytes. Note that older drive technologies used to use just three widths of magnetic-pulse regions, the widest of which was three times the width of the narrowest. Newer drive technologies use many more widths, since the width of the narrowest region the media can support is considerably wider than the minimum discernible distance between widths. In the 1980's, increasing the number of different widths on a drive with a given minimum width would increase usable capacity by 50%. I don't know what the ratio is today.
Information on a randomly-writable disk is divided into sectors, each of which is preceded by a sector header; the sector header is itself preceded and followed by a gap. Both the sector header and the sector begin with special patterns of region widths which cannot occur anywhere else. To read a sector, a drive watches for the special pattern that indicates "sector header", then reads the bytes that follow it. If they match the sector the drive wants, it then watches for a pattern indicating "data header" and reads the associated data. If the data does not match the sector of interest, the drive goes back to looking for another "sector header".
Writing a sector is a little trickier. Drive electronics take a short but non-zero (and not entirely predictable) amount of time to switch between reading and writing mode. To deal with this, drives only write data a whole sector at a time. To write a sector, the drive starts in read mode, waits until it sees the header of the sector to be written; then it switches to write mode, outputs the data, and then switches back to read mode. Because there are gaps before and after the data area, it won't matter if the drive sometimes switches to write mode a little faster or slower, provided that (1) the "start" pattern for a block is preceded by some data that doesn't match the start pattern, so that even if the drive starts "late", the portion of the old block that isn't erased won't match the start pattern (2) the drive must start early enough that it finishes before the start of the next sector.
When reading data, one determines what data is represented by a particular spot on the disk by "counting" the magnetic regions seen since the previous start-of-block marking. When writing data, what data is represented by the spot on the disk the head is passing will be determined by the controller's count of the amount of data written so far. Note that there is no way of predicting precisely which bit will be represented by any spot on the disk before it is written, since there is a certain amount of "slop" in the writing process.
supercat
- 45,939
- 2
- 84
- 143