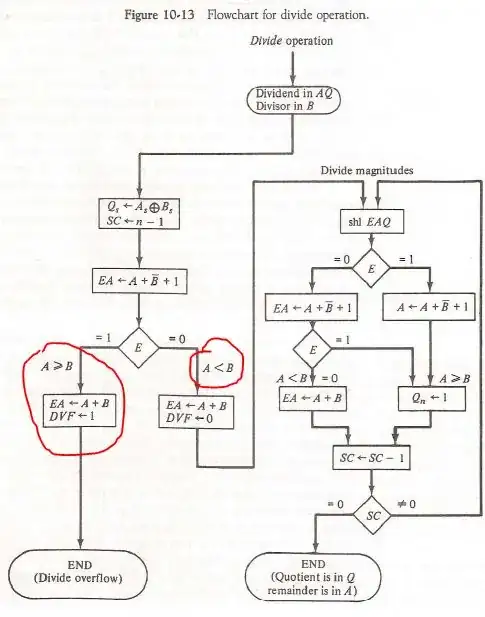
I have tried hard but I don't understand how this algorithm is working.Please explain the flow chart.
\$DVF\$ is the divide overflow flip flop.
\$A_s\$ is the sign bit of \$A\$
\$B_s\$ is the sign bit of \$B\$
\$E\$ is the register that has a carry bit
Initially the XOR operation is carried out to check if the sign bits of two numbers is equal.
The dividend is \$A\$ and \$Q\$ and the divisor in \$B\$. The sign of the result is transferred into \$Q_s\$ to be part of quotient. \$SC\$ is the sequence counter.
I am unable to understand the sequence of operations . What happens after the carry bit is checked for 1 or 0 ?