What I would do: first try to find the fundamental frequency. A speaking voice does not have a fixed note in this sense, so you need to do it quite quickly-responding, a direct phase-locking method may be better than doing it with FFT. Then feed this frequency into a comb filter, to remove the fundamental and all its overtones. What remains is then, ideally, only pop and hiss noises, both either quite low or quite high-frequency, so bandpassing the midrange should – for a clear and single voice signal – leave only a very weak remaining signal. For music or other noises on the other hand, you have a wide mixture of frequencies throughout the midrange, so combfiltering will not weaken the RMS very much at all. So a high level after the comb/bandfiltering process will indicate that the source was not clean voice.
I tried this with a simple SynthMaker program,
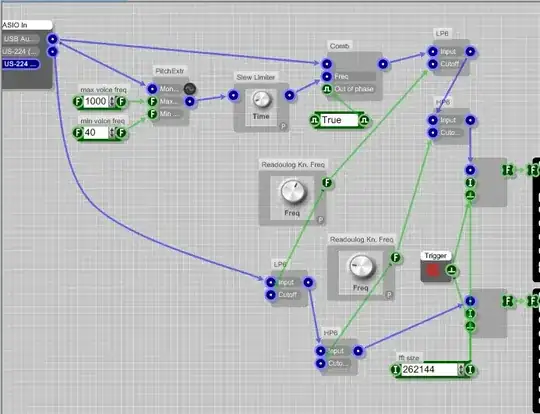
and it is not really reliable yet but does in principle work.
Result for speech alone:
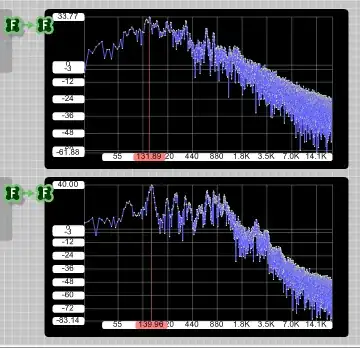
The combfiltered signal is 6 dB weaker than the only-bandpassed one.
Result for music (speech+acoustic guitar, just to test):
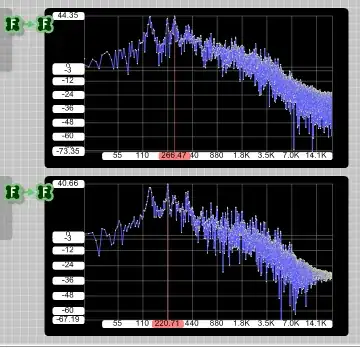
Here, the combfiltered signal is actually louder (the filter is wrongly normalized).